
Нейросети архитектуры Transformer
На сегодняшний день (февраль 2019) лучшие результаты в решении основных задач NLP получены нейросетями т.н. архитектуры Transformer, предложенной исследователями компании Google в декабре 2017-го году в статье Attention Is All You Need. За этим последовала публикация материалов по GPT от OpenAI, затем последовал ответ от Google с нейросетью BERT, после чего OpenAI выложили сильно урезанную версию GPT-2, заявив, что общество не готово к публикации всей предобученной нейросети GPT-2.
Давайте разберемся, что из себя представляет нейросеть типа Transformer и чем она может быть нам полезна. Первое, что бросается в глаза: Transformer - НЕ рекуррентная сеть. Забавно, что 3 дня назад (23.02.2019) вышла статья частично тех же авторов Universal Transformers, где предложена рекуррентная сеть архитектуры Transformer.
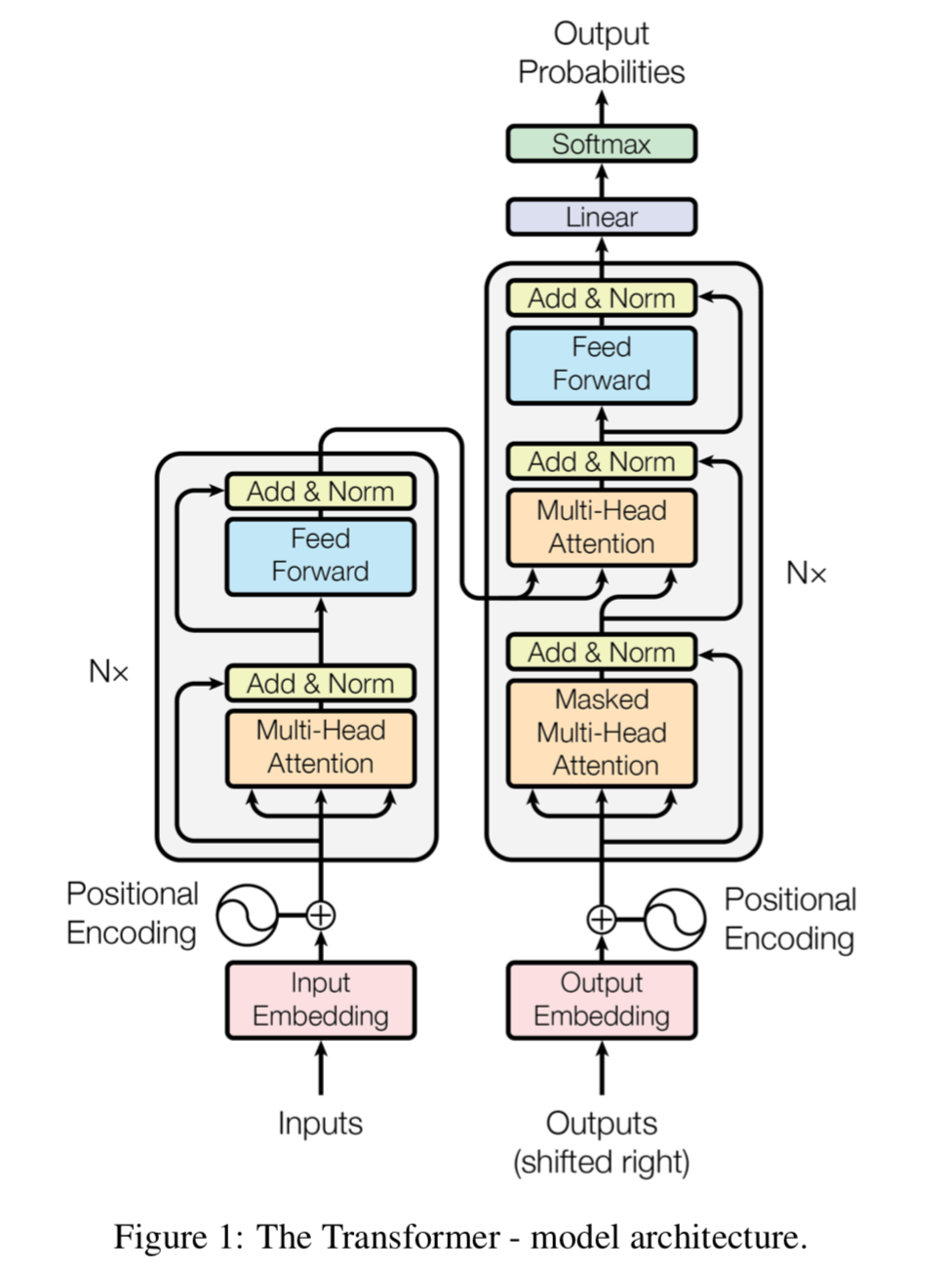
Нейросети на архитектуре Transformer могут использоваться для самых разных задач NLP, однако основными “учебными” задачами будут восстановление пропущенных слов в предложении и оценка логического следования одного предложения из другого. По некоторой причине, для кодирования предложения или их пар (далее будем говорить “текст”) используются вектора длины 512. (Кстати, на днях Google опубликовали пример использования BERT в TF HUB, и там длина вектора равна 128). Представление текста состоит из трех векторов длины 512 и осуществляется следующим образом:
-
вектор token_input начиная с 0-й позиции содержит индексы “токенов”, остальные элементы заполняются нулями. Под токенами могут пониматься словоформы, словосочетания, а также части словоформ, например, приставки, корни или окончания. Так, например, если текст разбит на 10 “токенов”, то в векторе token_input первые 10 позиций заполняются индексами “токенов” из словаря, а остальные - нулями;
-
вектор mask_input кодирует пропущенные слова (т.н. “маски” [MASK]): если тот или иной “токен” скрыт маской, в соответствующую ячейку мы записываем единицу, остальные ячейки заполняем нулями;
-
вектор seg_input кодирует, какие “токены” относятся в первому предложению, а какие - ко второму: если “токен” принадлежит ко второму предложению, в соответствующую ячейку мы записываем единицу, остальные ячейки заполняем нулями.
Кодирование позиции (Position Encoding)
Поскольку нейросети архитектуры Transformer не являются рекуррентными, необходимо некоторым образом закодировать позицию каждого токена в каждом конкретном обучающем примере. Для этого используется техника, именуемая Position Encoding. Для каждого токена для каждого базиса в 512-мерном пространстве задается значение синусоиды или косинусоиды по следующим формулам:
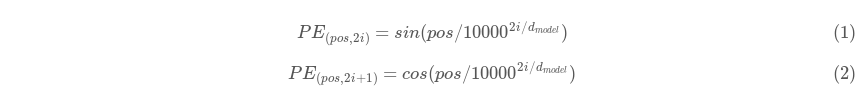
где pos - индекс позиции токена в тексте, а i - номер базиса в 512-мерном пространстве, т.е. i “пробегает” от 0 до 255.
Таким образом для каждого токена мы получаем 512-мерный вектор “времени”. Далее мы прибавляем этот вектор к векторному представлению токена (также 512-мерному) и получаем тоже векторное представление токена, но с поправкой на его позицию в тексте.
Механизмы внимания (Attention)
Собственно, название статьи, в которой была впервые описана архитектура Transformer, дает понять, что в основу соответствующего класса нейросетей положены т.н. механизмы внимания, ранее хорошо себя зарекомендовавшие в нейросетях типа Seq2Seq в качестве вспомогательного элемента. Вообще говоря, ранее казалось, что механизмы внимания хороши именно для машинного перевода, когда у нас есть пары предложений на исходном и результирующем языке и мы хотим сопоставить словоформы из разных языков, имеющих близкую дистрибутивную семантику. Однако затем стало ясно, что между двумя подряд идущими предложениями из одного текста существует множество связей, позволяющих “переводить” i-е предложение в i+1-е и этот перевод удобно осуществлять с использованием механизмов внимания и только их. Более того, внутри одного предложения существует множество связей, которые удобнее всего моделировать механизмами внимания. Все это вылилось в задачи, соответственно, оценки логического следования одного предложения из другого и восстановления пропущенных слов в предложении.
Давайте разберемся с несколькими базовыми понятиями механизмов внимания.
-
Самовнимание (Self-attention). Под самовниманием понимается механизм внимания, когда исходная и результирующая последовательности совпадают. Как вы догадались, данный механизм удобно обучать на задаче восстановления пропущенных слов в предложении.
-
Многоголовое внимание (Multi-head attention). Как вы догадались, “самовнимание” осуществляет что-то вроде нечеткого синтактико-семантического анализа предложения. Задача механизма многоголового внимания состоит в том, чтобы попытаться некоторым образом разделить “синтактико-семантический”, например, на синтаксический и семантический, а синтаксический, скажем, условно разделить на связи по частям речи и связи по падежам. Строго говоря, под числом “голов” понимается число принципов, по которым те или иные элементы предложения связаны между собой, по форме или содержанию. Дефаззифицируя те или иные головы, мы можем автоматически получать, например, синтаксические деревья без единого примера синтаксического разбора предложения. Мощность множества голов обозначается как h, в нашем случае h = 8. При размерности модели d_model = 512, мы имеем d_k = d_v = d_model/h = 64. В стандартной же модели BERT используется h = 12 и d_model = 768, так что d_k = d_v = d_model/h = 64. Вот такой простой способ деления на головы разбиением на подпространства. Заметим что d_model является размерность векторного представления.
-
Внимание взвешенного скалярного произведения (Scaled Dot-product attention). Здесь мы подошли к основной формуле вычисления внимания:
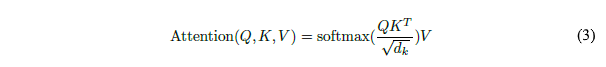
где Q (от англ. Query - ‘Запрос’) - т.н. ‘from_tensor’, т.е. множество элементов предложения, для которых мы ищем соответствие; K (от англ. Key - ‘Ключ’) - т.н. ‘to_tensor’, т.е. множество элементов предложения, среди которых мы ищем соответствие элементам Q; V (от англ. Value - ‘Значение’) - совпадает с K в данной модели.
Давайте попробуем понять логику данного выражения. Пусть мы имеем вариант, при котором мы рассматриваем одно предложение. Тогда каждому токену мы ставим в соответствие каждый токен…
Обратимся к исходному коду сети BERT. Для создания модели нам необходимо вызвать метод transformer_model (см. modeling.py). Совокупность входных выражений (наших текстов) представляется в виде тензора input_tensor, с формой [batch_size, seq_length, hidden_size], где batch_size - размер batch’а, seq_length - фиксированное число токенов в тексте, а hidden_size - размерность пространства векторных представлений. Одним из аргументов метода transformer_model является num_hidden_layers - гиперпараметр, сообщающий функции число блоков Transformer. Все блоки одинаковы, в основу каждого из них положен слой внимания Attention Layer. Данный слой моделируется методом attention_layer. Данный метод получает на вход два тензора: from_tensor и to_tensor. Из метода transformer_model мы знаем, что from_tensor = input_tensor и to_tensor = input_tensor, т.е. на данном этапе они равны. Такая модель как раз называется Self-Attention. Слой внимания состоит из подслоев query_layer, key_layer, value_layer и context_layer. Каждый из них является Dense-слоем, причем query_layer получает на вход from_tensor, а key_layer и value_layer - to_tensor. Затем мы покоординатно перемножаем выходные значения query_layer и key_layer: attention_scores = tf.matmul(query_layer, key_layer, transpose_b=True). Затем получим ‘взвешанное’ значение attention_scores: attention_scores = tf.multiply(attention_scores, 1.0 / math.sqrt(float(size_per_head))). Нормализуем значения функцией Softmax: attention_probs = tf.nn.softmax(attention_scores). Используем функцию Dropout для борьбы с переобучением: attention_probs = dropout(attention_probs, attention_probs_dropout_prob). На выходе из слоя внимания имеем: context_layer = tf.matmul(attention_probs, value_layer).
Тестируем предобученную модель: “В предложении много крылатых [MASK]”
В качестве теста мы выбрали удобную keras-bert с предобученной многоязычной нейросетью BERT архитектуры Transformer. Запустили нейросеть в Google Colab и попросили угадать, что же скрыто под маской в выражении: “В предложении много крылатых [MASK]”. Вот что нам ответила нейросеть BERT: “В предложении много крылатых птиц”. Разумеется, мы ожидали увидеть: “В предложении много крылатых выражений”. Последовали десятки более тривиальных примеров и ни одного совпадения. Пожалуй, BERT условно справилась только с некоторыми глаголами. Условно, потому-что писала “сказала” вместо “подумала”, что мы можем засчитать как правильный ответ.
Тестируем RuBERT
…